
Clustering
Clustering is bunching observations (people’s microbiome) into groups based on similarity. In english, we want to see if one people with shift in one type of bacteria also have a shift with a different type.
Phylum Level
I am starting by looking at a higher level, so there are less factors to consider. The data is easy to download. [phylum <-read_csv(“http://lassesen.com/ubiome/TaxonomyByphylum.csv”) ]
After this we scale the data and proceed to explore.
First a Box Plot
This shows the odds of outliers (data is scaled remember). We see Bacteroidetes are well behaved (normal distribution), but phylums like Actinobacteria, Verrucomicrobia, Proteobacteria, and Firmicutes have atypical behavior.

Bacteroidetes vs Firmicutes
These are the dominant two phylum. When we plot the data we see a clear ‘trade off’ pattern between them. We also see that there is a number where Bacteriodetes < 0.1 (scaled).

Filtering to these low ones (86), removing the sampleId column, and searching for number of clusters that would classify these many observations, we see that there an ‘elbow’ at 3

Applying a dendrogram, we see that these 86 people fall into some distinct groups.

Plotting the cluster illustrates that we have good separation.
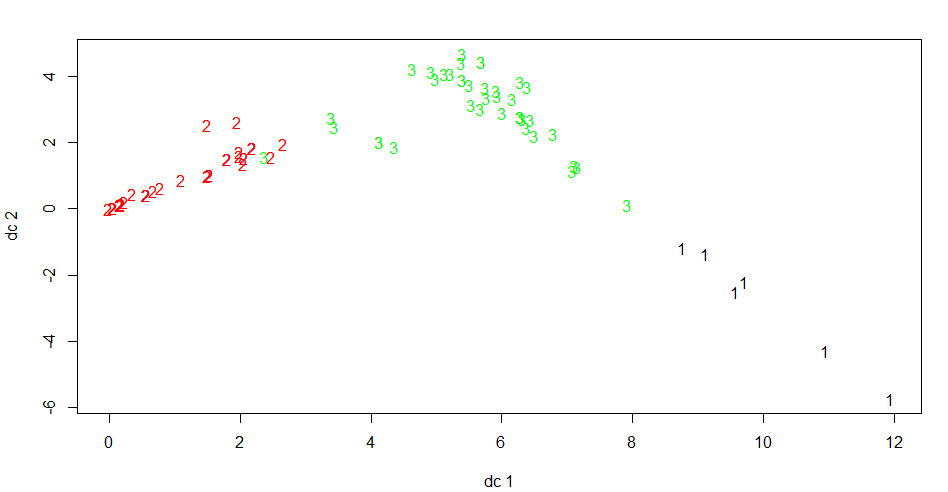
Looking at the averages by phylum for each of the groups we see some clear patterns:

We originally filter to Bacteroidetes < 0.1, but we see that this group could be divided into very very low (Groups 1 +2) and low (3).
Returning to other Phylum
Three plots are shown below — Actinobacteria, Verrucomicrobia, Proteobacteria



Odd line is seen below — almost a straight inverse line for one set of data

Homework
My purpose is to get people exploring the data. If you look at Data Science: Tax Rank and Symptoms, you can find the sampleIds with symptoms (a subset of the data above). The assignment is simple — can you find any symptoms that appear to be associated with the clusters you may have found?
You may wish to pre-filter to only the phylum with symptoms… and then cluster.
