
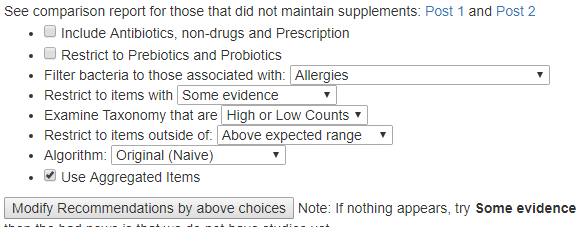
Creating suggestions on http://microbiomeprescription.com/ is an art and not a science. I recently added choice of algorithms:
To illustrate, you have 4 bacteria:
- A 2x normal
- B 8x normal
- C 1/2 normal
- D 1/100 of normal
If A is normally 0.1% of bacteria and B is 10% of bacteria – do you treat them the same? B produces 100x more metabolites than A… so likely it is better to reduce B than reduce A.
Some herb reduces B (10% of population) and also reduces D which is 0.001% of the normal population and only 10% of patients have any of this bacteria. Do you take the herb or not?
The process of balancing factors such as:
- Percentage of total bacteria
- How often do people have this bacteria
- Side-effects on other bacteria
- How much shift we see
is what algorithms are about. If you restrict items to only what reduces your high bacteria OR encourages your low bacteria… you will have nothing in the suggestions.
A simple algorithm could be something like this for each substance
- Sum up all of the high bacteria it reduces and the low bacteria it increases and use this to rank suggestions.
- Problem: you are ignoring the low bacteria that may also be reduced and the high bacteria that may be further increased!
- Sum up all of the high bacteria it reduces and the low bacteria it increases. Then subtract the high bacteria that it increases and the low ones that are reduced. Use this to rank suggestions.
- Problem: A bacteria that is 10% of the bacteria is given equal weight to one that is just 0.00001% of the bacteria.
- Sum up all of the high bacteria it reduces and the low bacteria it increases using the expected percentage of the population. Then subtract the high bacteria that it increases and the low ones that are reduced using the expected percentage of the population. Use this to rank suggestions.
- Problem: We are ignoring if the overgrowth is 10% or 800%!
Then we hit the question of — do we know anything abiut what this bacteria does? If this bacteria is not associated with any known condition and only occurs in 10% of the population…
Take: Propionibacteriaceae (14.35% of Samples) family a recent paper explains why — only 14% have it… so do we need to reduce or increase it??? Honestly, we do not know and I would exclude it from adjustments.
“For example, for SNP rs2297345 in the gene PAK7, we detected a correlation between genotype and a single microbial taxon, Propionibacteriaceae”
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5740987/
Formal Statement
- S() returns a vector of factors
- Output vector including, but not limited to
- Taxonomy
- Estimate of change for each taxonomy
- Reliability of change for each taxonomy
- DNA Snp factors
- Input matrix including, but not limited to
- Study
- Study size
- Study statistical significance
- Shift reported by the study
- Species involved
- Background diet
- Existing conditions or DNA
- Output vector including, but not limited to
- B() is a person matrix including, but not limited to
- Taxonomy
- Population size
- Statistical error factors
- R() is a reference matrix including, but not limited to
- Taxonomy
- Population size
- Statistical error factors
- Distributions broken down by:
- Medical conditions
- DNA
- Age
- Lab results
- H() is a matrix of a person (the target), including, but not limited to
- Medical conditions
- Laboratory results
- DNA
- Ethnic background/heritage
- Age
- Normal Diet
Predictions are the output vector from P(H(…),B(…), S(….), R(….))
The algorithms that I have implemented are Trade Secrets, do not ask me to disclose them.
Bottom Line
Suggestions come out of algorithms that attempts to balance a ton of different factors. The sequence of suggestions will likely change between algorithms and it is unlikely something would move between the take and avoid list.
There are two algorithms there at the moment, I will likely add more. Which one is best? We do not know.
